今回はZOOM社のマルチストンプのMIDI制御についてです。
一年前ぐらいにUSBHOSTでMIDI制御しましたがいろいろ発見があったので今回こうして書いているわけです。
前回は単一チャンネルの変換を行ったが今回はDMAを使ったものをやって行こうと思う。
ADCは変換終了フラグ(EOC)を見てDRレジスタを見に行くことで変換データを得ることができる。

上記の図のようにシーケンスの終了でもフラグが立つ(EOS)
二つのフラグを見てソフトウエア的に行うこともできるがタイミングがずれるとDRのデータが上書きされてしまう。
それを防ぐ仕組みにオーバーランというものある。
これはデータを保護できるがそのあとの変換値は破棄されてしまうので注意が必要だ

そのため複数チャンネルを変換する場合EOCフラグをトリガとしてDMAでレジスタ→メモリを実現したほうがソフト的な介在がなくなるので楽に処理できる。
マニュアル曰く(RM0316 345ページ)
変換されたチャネルの値は特定のデータレジスタに格納されるので、複数のチャネルの変換には
DMA の使用が便利です。これによって、ADCx_DR レジスタにすでに格納されているデータの損失を防ぐことができます。
DMA モードが有効なとき(ADCx_CFGR レジスタの DMAEN ビットがシングル ADC モードで 1 にセットされている場合、またはデュアル ADC モードで MDMAが0b00 以外に設定されている場合)、
各チャネルの変換後、DMA リクエストが生成されます。これにより、変換データを ADCx_DR レジスタからソフトウェアで選択した場所へ転送することができます。
これにもかかわらず、DMA が DMA 転送リクエストを時間内に処理できなかったためにオーバーランが発生した場合(OVR=1)、ADC は DMA リクエストの生成を停止し、新しい変換に対応するデータ
は DMA によって転送されません。
これは、RAM に転送されるすべてのデータを有効とみなすことができることを意味します。
要するにCH変換ごとにDMAリクエストが生成されるということ。
オーバーランが発生するとDMAがとまる。
OVRMODを適切に処理するか頻繁に止まるようならDMAを時間内に処理できるように変換自体の速度を下げておくなど工夫が必要だ。
DMAのモードには
の2つがあり
ワンショットは一回きりの転送になります

一方サーキュラは連続的にADCのCH変換が終わるたびにDMAリクエストが生成するので連続的なストリームが構成できる。




ここでアドレスのインクリメントにチェックを入れておくといい感じに配列に格納できる。
参考までに動いたコードを示しておく
ADC終了時に呼ばれるコールバック内にprintfを入れてUART出力している。
3日間ぐらいかけてADCやってみたんだけど何だかんだDMAを使ったのが一番簡単だねぇ
DMAといったら結構難しいイメージあったけどCubeMXのおかげでほとんど設定してくれるのでかなり楽ですね。
3日間一緒に検討してくれたリアルテック先生には感謝です。
http://realteck-blog.netlify.com/2017/04/08/f031%E3%81%AEadc%E9%80%A3%E7%B6%9A%E5%A4%89%E6%8F%9B%E3%81%8C/realteck-blog.netlify.com
2017/5/18追記
お恥ずかしいお話なのですがオカダといろいろやってて複数のADCを使うとMainにブレーク立てても帰ってこないと2日間ぐらい悩みました。

んで上記の図のようにこいつのADCには低速チャネルもあるんです。
12ビット精度で変換する場合最低でも14サイクルかかります

高速の場合Cubeで19.5サイクルにすればよいのですが低速の部分も19.5にしてました・・・・・ほんと雑魚wwww
なので皆さんはこんなバカなことで時間とかしちゃだめですよ!
直すとちゃんと動く
追記 2019/3/12
自分の場合上記のコードで動いたのですがshyachiさんより指摘があったので載せときます
/* USER CODE BEGIN 2 */ if (HAL_ADC_Init(&hadc2) != HAL_OK) { Error_Handler(); } if (HAL_ADC_ConfigChannel(&hadc2, &sConfig) != HAL_OK) { Error_Handler(); }
の2つの関数はMX_ADC2_Initにてコールされているので呼ばなくて良さそうです。
特にHAL_ADC_ConfigChannelの方は呼ぶと2ch変換できなくなるケースも有るとか
動かない人はこの辺もお試しください
今回は一番簡単なやつやってみます。
やったことを雑に書くとこんな感じ
今回は一個しか読まないのでこのようにPA4にアサインする
一応UARTも使ってるのでそれも設定する
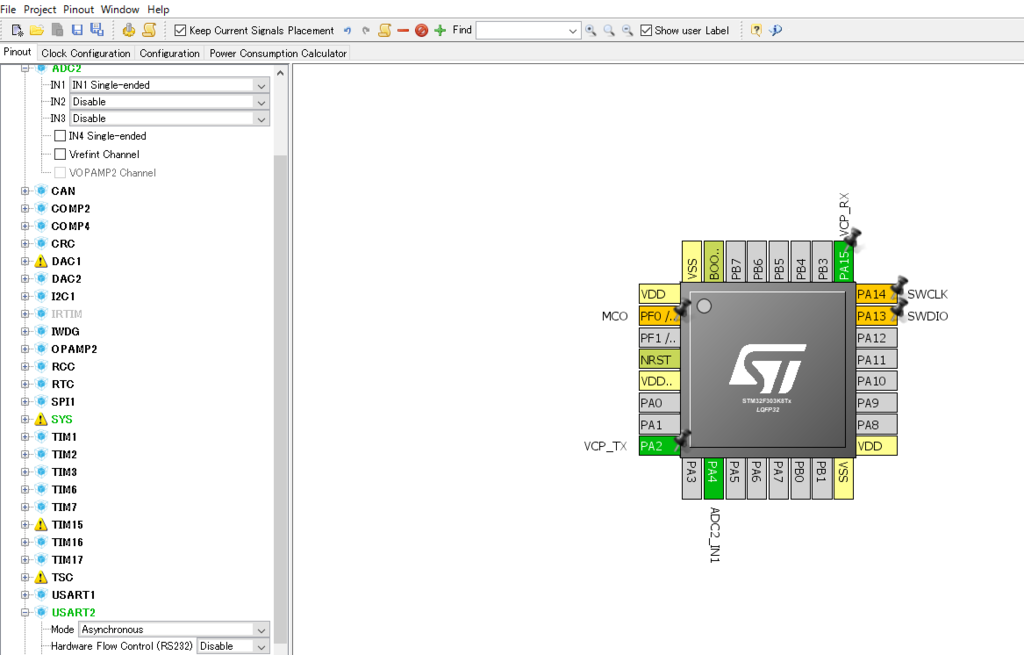
各種設定はこんな感じ

要所要所説明挟むとこんなもん
| 設定 | 機能 | 説明 |
|---|---|---|
| mode | independent mode | 独立モードで動く、その他速度を上げるDualModeがある |
| Clock Prescaler | 非同期、1~4分周 | 読んで字のごとくクロック分周器 |
| Resolution | 6~12bit | ADCの分解能 |
| Data Alignment | 右詰め、左詰め | データの詰め方 |
| Scan Coversion | Enable,Disable | 一回のシーケンスですべてのCHを変換するかどうか |
| Continuos Conversion Mode | Enable,Disable | 連続変換 |
| Dis Continuos Conversion Mode | Enable,Disable | 不連続変換 |
| End Of Conversion Selection | シングルごとかシーケンスごとか両方か | 変換終了フラグの有無 データシートEOCフラグの部分読んだほうが図もあってわかりやすい |
| Low Power Auto Wait | Enable,Disable | 自動遅延変換モードの有無。ADC オーバーランが発生するリスクのある低周波数のクロックで動作しているアプリケーションのパフォーマンスを最適化する場合に有効 |
| 設定 | 機能 | 説明 |
|---|---|---|
| Enable Regular Conversion | Enable,Disable | レギュラー変換の有効化 |
| Number of conversion | 変換数 | チャンネル数分設定できる |
| External Trigger Conversion Source | ソフトおよびタイマートリガ | 変換トリガソースの設定。 タイマーとかに連動できる |
| External Trigger Conversion Edge | 立ち上がりか立下りかソフトか | 外部割り込みの設定 |
RankはCH分だけ個別設定ができる
| 設定 | 機能 | 説明 |
|---|---|---|
| Channel | チャンネル数分設定できる | 設定したいCHを入れる |
| SamplingTime | 1.5~601.5サイクル | サンプリングタイム |
| OffsetNumber | 1~4 | オフセットするCHの選択 |
| Offset | 1~4056 | 変換値のオフセット |
一応紹介しておく
POTの2番ピンをA3ピンにつないでいるだけだが

参考までにコードを貼っておく
今回は高速に三角関数とかを計算できるARM社提供ライブラリであるCMSIS DSPライブラリを使ってみる話です。
こいつを使うとsin,cosとかよく使う三角関数やaddとかを高速に処理できます。
そのほかFIR,IIRと言ったデジタルフィルタ用のAPIだったり制御用のAPIもあるのでつかわない手はないです。
今回の実習環境は以下の通りです
CubeMXで適当にプロジェクトを作ってビルドが通るとこまで作っておきます。
次にコンパイル済みのライブラリを追加していきます。
オブジェクト自体はCubeF7のフォルダ内にあります。
場所を調べるには
CubeMX上記メニューからhelp->UpdaterSettingでパスをコピーします

ファイルエクスプローラーでそこに移動します。
するとこんな感じのファイル構成になっていると思います

オブジェクトは以下のPATHにあります。
STM32Cube\Repository\STM32Cube_FW_F7_V1.6.0\Drivers\CMSIS\Lib

三つありますがダブルポイント(倍精度)かシングル(単精度)かを選ぶ。
今回はF767なのでdpがついてるlibarm_cortexM7lfdp_math.aを選びます。
それをコピーしてプロジェクト直下にいれます。

プロジェクトのプロパティーを開く
「C/C++Build」/GCC linker/Miscellaneous欄で
Linker、LibrariesでDSP処理のLinkerとかを設定していく
arm_cortexM7lfdp_math.a
ものによってはエラーになるので.aをなくした版で試して見てください
arm_cortexM7lfdp_math
ヘッダーをインクルードします。
#include "arm_math.h"
今回は試しに平方根でもやってみます。
FastMathのとこに入ってます。
CMSIS DSP研究室さんで詳しく解説されています。
APIとしては
arm_sqrt_f32 (float32_t in,float32_t * pOut )
を用います
こんな感じに書いた

何だかんだこのシリーズも6個目ですねw
前回まででUARTの基本的な使い方はマスターしたと思います。
今回はCubeMXでの出力は詳しくは解説しないので
まだの方は1から読んでみてください
gsmcustomeffects.hatenablog.com
gsmcustomeffects.hatenablog.com
gsmcustomeffects.hatenablog.com
gsmcustomeffects.hatenablog.com
gsmcustomeffects.hatenablog.com
今回の環境は以下に示す通り
とりあえずCubeでUART2を有効にしてボーレートを各自設定しファイルを出力する。
ココまでは今までと同じです。
syscall.cがCにおけるスタンダードライブラリを読んでいるのでそれをどっかからもってこないとリンクできないわけです。
とりあえずSTが提供するサンプルには入っているのですがCubeMXが出力するsrcフォルダには入っていません。
なのでAc6で適当な空プロジェクトを作る必要があります。
めんどかったらSTが提供するサンプルから引っ張ってくるという方法もあります。

で今回使うボードを選択

CubeHALを選択

そうするとsyscall.cができるのでそれをCubeMXが出力したSrcにコピーしてくる


んで一度コンパイルします。
syscall.c内では
__io_putchar(int ch) __attribute__((weak))
のようにWEAK定義されているのでMain内で再定義してこっちを使うよということをコンパイラに教えてあげる作業をします
こういうふうにします。
#ifdef __GNUC__
#define PUTCHAR_PROTOTYPE int __io_putchar(int ch)
#else
#define PUTCHAR_PROTOTYPE int fputc(int ch, FILE *f)
#endif /* __GNUC__ */
void __io_putchar(uint8_t ch) {
HAL_UART_Transmit(&huart2, &ch, 1, 1);
}
printfというのは内部で書式を整えてputcharを呼び出しているのでそのputcharの内部をHALの一文字送信APIに置き換えるということです。
コンパイルマクロがGNUとかついてるのはARMの純正コンパイラではfputcと定義されてるのでコンパイラごとに読み替えが効くようにしているためです。
次にprintfを呼ぶ前にどこか最初以下の行を挿入します
setbuf(stdout, NULL);
これはprintfの仕様みたいで1024byte入れた後に呼ばれるのでコレがないと変なハンドラに飛びます。
とりあえずバッファをフラッシュするといいみたいです。
ここまででとりあえずint型のprintfは動きます。
だいたい15KBぐらいになります。
リンカーオプションにfloatを追加して再ビルドする必要があります。
やることとしてはlinkerのフラグ部分に-u _printf_floatというのを追加するだけです。

それであとはApplyして再ビルドします。

結構サイズがでかくなります。
いうてGCCならKEILと違って32KB以上もビルドできるしFloat扱うようなマイコンはフラッシュ自体大きい物がのってるので特に悩まないかと思います。
ARMのソフトウエア駆動割り込みの覚え書きです。
ARMの割り込みはNVIC(統合ネスト型ベクタ割り込みコントローラ)で管理されていますがその中でSTIRというレジスタがあります

図で言うと赤の部分ですね
詳細はこちらになります

Write to the STIR to generate an interrupt from software
とあるように割り込みの番号を入れてやるとソフトウエアから割り込みを生成できるようです。
実際の使い方はこのような感じです。

STM32の場合IRQ番号はstm32f767xx.hに定義されています

ためしにピン割り込みハンドラにソフトウエアから移動してみます

図ではわからないですがスイッチを押さなくても割り込みハンドラに遷移しています。
もちろん割り込みも有効なのでスイッチを押すとそのタイミングでも割り込みがかかります。
なのでこの割り込みを使う際は使わないであろうペリフェラルを殺しておいて使うほうがいいでしょう