色々試してたらGCCの場合最適化しないとFPU命令呼んでくれないっぽい

optimize入れるとちゃんと呼ばれてる

i.MX RT1020(CortrexM7 DP FPU)のSQRTしか試してないのであれですが入れとくに越したことはないかと。
尚、消されたくない変数にはvolatileを付けましょう。
以上
色々試してたらGCCの場合最適化しないとFPU命令呼んでくれないっぽい
optimize入れるとちゃんと呼ばれてる
i.MX RT1020(CortrexM7 DP FPU)のSQRTしか試してないのであれですが入れとくに越したことはないかと。
尚、消されたくない変数にはvolatileを付けましょう。
以上
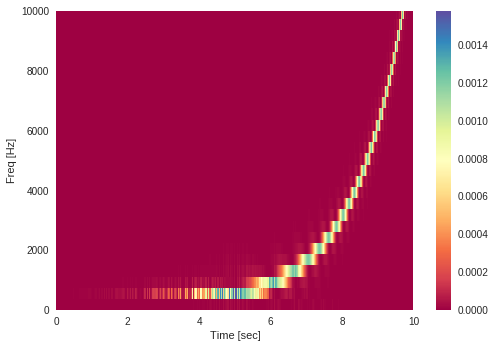
今回は信号の時系列変化を可視化できるスペクトログラムについてです。
使うメソッドはPython:scipy.signal.spectrogramです。
オプションパラメータがたくさんありますが
f,t,Sxx = signal.spectrogram(data, fs, nperseg=512)
のように書いてあげればいいです。
今回は前回作成したSwept-sine信号のスペクトラムの描画をやってみたいと思う
信号の生成は前回の記事を参考にしてほしい
gsmcustomeffects.hatenablog.com
今回やることとしてはsignal.spectrogramメソッド呼ぶだけ
import matplotlib.pylab as plt import numpy as np import scipy.signal as signal f1 = 10 # start frequency f2 = 12000 # end frequency fs = 96000 # sampling frequency T = 10 # time duration of the sweep fade = [48000, 480] # samlpes to fade-in and fade-out the input signal '''generation of the signal''' L = T/np.log(f2/f1) # parametre of exp.swept-sine t = np.arange(0,np.round(fs*T-1)/fs,1/fs) # time axis s = np.sin(2*np.pi*f1*L*np.exp(t/L)) # generated swept-sine signal # fade-in the input signal if fade[0]>0: s[0:fade[0]] = s[0:fade[0]] * ((-np.cos(np.arange(fade[0])/fade[0]*np.pi)+1) / 2) # fade-out the input signal if fade[1]>0: s[-fade[1]:] = s[-fade[1]:] * ((np.cos(np.arange(fade[1])/fade[1]*np.pi)+1) / 2) f,t,Sxx = signal.spectrogram(s, fs, nperseg=512) plt.figure() plt.pcolormesh(t,f,Sxx,cmap="GnBu") plt.xlim([0,10]) plt.ylim([0,10000]) plt.xlabel("Time [sec]") plt.ylabel("Freq [Hz]") plt.colorbar() plt.show()
matplotのcmapの設定で好みの色に設定できる

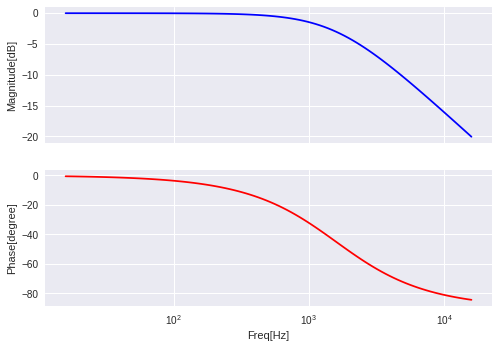
今回はScipyのsignal.bodeを使って周波数応答を描画してみる。
使うメソッドは
である。
線形時不変システムを作成できるメソッド。引数の渡し方によって伝達関数だったり状態空間モデルとかいろいろ定義できる。
詳しくは公式ドキュメントが参考になる。
scipy.signal.lti — SciPy v1.8.0 Manual
というのを作りたかったら
from scipy import signal # transferfunc = 10000 / s+10000 s = signal.lti([10000], [1.0,10000])
とすれば良い
次にボード線図の方だ
これもドキュメント読んでもらえればわかるんだけど(scipy.signal.bode — SciPy v1.8.0 Manual)

基本的にLTIで作ったインスタンスを入れてあげればw,mag,phaseが帰ってくる感じ.
見た感じARMAモデルそのまま打ち込んでも表示してくれるみたい
w[radian/sec]はグラフのx軸に当たる部分で正規化周波数で帰って来るのでfにしたい場合は2piで割れば良い
実際の使い方はこうなる
w, mag, phase = signal.bode(s)
最後に全体のコードを張っておく
import numpy as np from scipy import signal import matplotlib.pyplot as plt # transferfunc = 10000 / s+10000 s = signal.lti([10000], [1.0,10000]) w, mag, phase = signal.bode(s) f = w/(2.0*np.pi) fig, (ax0, ax1) = plt.subplots(nrows=2, sharex=True) ax0.semilogx(f, mag, 'b-') ax0.set_ylabel("Magnitude[dB]") ax1.semilogx(f, phase, 'r-') ax1.set_ylabel("Phase[degree]") ax1.set_xlabel("Freq[Hz]") plt.show()
自分用メモです。
これ一つで取りあえずはwav読み込みとFFTのサンプルかねてるので参考になれば
import soundfile as sf import numpy as np import matplotlib.pyplot as plt from scipy import fftpack fname = 'whitenoise.wav' # mono data, samplerate = sf.read(fname) X = fftpack.fft(data) freqList = fftpack.fftfreq(len(data), d=1.0/ samplerate) amplitude = [np.sqrt(c.real ** 2 + c.imag ** 2) for c in X] # 振幅スペクトル # 波形を描画 # 振幅スペクトルを描画 plt.plot(freqList, amplitude, marker='.', linestyle='-',label = "fft plot") plt.axis([0, 25000, 0, 2000]) plt.xlabel("frequency [Hz]") plt.ylabel("amplitude")

2020/5/6
追記この記事では実データでフィッティングを行っています。
データ自体はご自分で用意していただく形になるのでそのまま実行するだけでは動きません
あくまでlmfitの使い方の一例として捉えていただけると幸いです。
尚初期値、モデルの与え方によっては収束しない、フィッティングがうまく行かないことがあります。(理論を勉強すれば理由はわかるとおもいます。
今回は前回の続きでlmfitを使ったフィッティングを試して行きたいと思う。
ほとんどここのパクリだがバグの修正含め解説も入れているので勘弁してほしい
Peak fitting XRD data with Python - Chris Ostrouchov
さっそくやって行こうと思うが
実用的なもので使わないと意味がないので今回はXRD(X-ray Diffraction)のピークフィッティングを例にしてフィッティングしてみたいと思います。
X-ray Diffractionは結晶性物質の解析に用いられる分析で結晶性物質の同定や結晶化度などを求めるときに使います。
以下に例としてゼオライトのXRDピークを示す。

XRDの解析ではこれらのピークをフィットしたりして使うことが多いと思います。
フィッティングにより非晶質ピークと結晶質ピークの面積がわかるのでそれらの割合から結晶化度を求めることが可能です。
全ピークフィットを行うと時間がかかりすぎるので範囲を絞って説明します。
今回は15度~21度範囲でのピークをフィッティングするスキームで進めます。

次にフィットモデルについてだがPeak-like modelsってのがLMFITには内蔵されている
XRDはピーク波形の集まりなのでそれを利用すると楽にフィットできそうである。
その中でもよく使うものを紹介しておく
where
まずはモデルを作る
def generate_model(spec)という関数を定義する
長いのでColabのリンクを貼っておく(リンク先のgenerate_modelって関数)
https://colab.research.google.com/drive/1At5-CseX7jhqPxjSyTk9gbIxC_dFRRU3#scrollTo=EdlAR8AoLbpa&line=26&uniqifier=1
途中でset_param_hintメソッドという新しい項目が出てきます。
これはモデルの最適化を行う際にある程度のヒントを与えるためのメソッドです。
各種説明は以下の通りです。

これ以外はPythonのビルトインメソッドの多様なのでゆっくり読み進めていけば困ることはないと思います。
次にこの関数に与える辞書リストをつくります。
いきなり作るのもあれなので
まずはピーク検出を行うための関数を作る。これにはScipyのfind_peaks_cwtメソッドを利用する。
こちらもColabのリンクで失礼する(update_spec_from_peaks)
https://colab.research.google.com/drive/1At5-CseX7jhqPxjSyTk9gbIxC_dFRRU3#scrollTo=YESpYSpYRyj6&line=2&uniqifier=1
簡単にモデルを与えてあげる
spec = {
'x': theta[int((15-5.0)/0.02):int((21-5.0)/0.02)],
'y': peak[int((15-5.0)/0.02):int((21-5.0)/0.02)],
'model': [
{
'type': 'GaussianModel',
'params': {'center': 26.5, 'height': 10, 'sigma': 1},
},
{
'type': 'GaussianModel',
'params': {'center': 26.14, 'height': 350, 'sigma': 0.1},
},
{
'type': 'GaussianModel',
'params': {'center': 26.8, 'height': 10, 'sigma': 0.08},
},
{
'type': 'GaussianModel',
'params': {'center': 27.12, 'height': 10, 'sigma': 0.1},
},
{
'type': 'GaussianModel',
'params': {'center': 27.5, 'height': 10, 'sigma': 0.1},
},
]
}
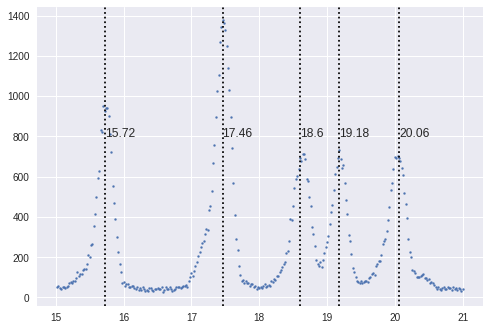
次にピーク検出したものをプロット
peaks_found = update_spec_from_peaks(spec, [0,1,2,3,4], peak_widths=(13,)) fig, ax = plt.subplots() ax.scatter(spec['x'], spec['y'], s=4) peaks = np.zeros((len(peaks_found),2)) j = 0 for i in peaks_found: ax.axvline(x=spec['x'][i], c='black', linestyle='dotted') ax.text(spec['x'][i],800, spec['x'][i]) peaks[j,0] = spec['x'][i] peaks[j,1] = spec['y'][i] j = j+1
これを使うとある程度のピーク位置が出てくる
そのままフィッティングしてみる
model, params = generate_model(spec) output = model.fit(spec['y'], params, x=spec['x']) fig, gridspec = output.plot(data_kws={'markersize': 1})

だいたいあっているがフィットしていない部分もある。3,4番目のモデルが当たっていない感があるのでそこのパラメータの与え方を変えてみる
spec['model'][2]['params']['sigma'] = 0.05 spec['model'][3]['params']['sigma'] = 0.05

綺麗にできたみたいなのでピークを分けてみてみる
fig, ax = plt.subplots() ax.scatter(spec['x'], spec['y'], s=4) components = output.eval_components(x=spec['x']) print(len(spec['model'])) for i, model in enumerate(spec['model']): ax.plot(spec['x'], components[f'm{i}_'])

最後にベストパラメータを出して終わり
def print_best_values(spec, output): model_params = { 'GaussianModel': ['amplitude', 'sigma'], 'LorentzianModel': ['amplitude', 'sigma'], 'VoigtModel': ['amplitude', 'sigma', 'gamma'] } best_values = output.best_values print('center model amplitude sigma ') for i, model in enumerate(spec['model']): prefix = f'm{i}_' values = ', '.join(f'{best_values[prefix+param]:8.3f}' for param in model_params[model["type"]]) print(f'[{best_values[prefix+"center"]:3.3f}] {model["type"]:16}: {values}') print_best_values(spec, output) #-------------------------------------------------------------------------------------------- center model amplitude sigma [17.460] GaussianModel : 428.469, 0.129 [20.031] GaussianModel : 253.663, 0.153 [19.180] GaussianModel : 210.520, 0.122 [18.621] GaussianModel : 254.223, 0.148 [15.726] GaussianModel : 284.501, 0.123
lmfitを使ったパラメータアシストフィットを行うことができた。
またモデルに推定ヒントを単一値を与えていたが範囲で与えることも可能なためその例も書いておいた。
今回のコード全容は以下にアップロードしているので皆さんのほうでカスタマイズしてみてほしい
https://colab.research.google.com/drive/1At5-CseX7jhqPxjSyTk9gbIxC_dFRRU3
今度はレーベンバーグマルカート法以外のメソッドで得たモデルパラメータを使った複合モデリングについて書いていきたい
実験データのフィッティングについて頻繁に使う機会があったので自分メモとしてまとめておきます。
フィッティングを行うにあたり、Numpy , Scipyには便利なライブラリがあります。
以上3つが結構有名です。簡単なフィッティングならScipy:optimize.curve_fitを使うのが一番楽だと思います。
import numpy as np import scipy.optimize import matplotlib.pylab as plt x = np.linspace(0, 2*np.pi, 100) y1 = np.sin(x) y2 = 0.5*np.sin(2*x) y_noise =(y1 + y2)+ 0.08 * np.random.randn(100) plt.scatter(x,y_noise) parameter_initial = np.array([0.5, 1.0]) #a, b, c # function to fit def func(x, a, b): return np.sin(x) + a*np.sin(b*x) paramater_optimal, covariance = scipy.optimize.curve_fit(func, x, y_noise, p0=parameter_initial) print(paramater_optimal) fitting = func(x,paramater_optimal[0],paramater_optimal[1]) plt.plot(x,fitting,color="red")

このように数行でフィットまでできるので
データがそろっていてモデルがある程度絞れているならこの方法が一番早いです。
ですがちょっと複雑なことしようとするとlmfitに軍配が上がるかもしれません。
Non-Linear Least-Squares Minimization and Curve-Fitting for Pythonってサブタイトルがついてる通り非線形最小二乗法を用いたモデルフィットのためのライブラリです。
scipy.optimizeの多くの最適化方法を基にして拡張したものでLevenberg-Marquardt methodの移植からプロジェクトが始まり様々な追加がなされています。
ざっと列挙すると以下があげられる。
lmfitの導入ですがpipなら簡単にできます。
pip install lmfit
その他Scipy,Numpy,matplotlibなんかが必要だった気がするのでご自分に合った環境づくりをしてください。
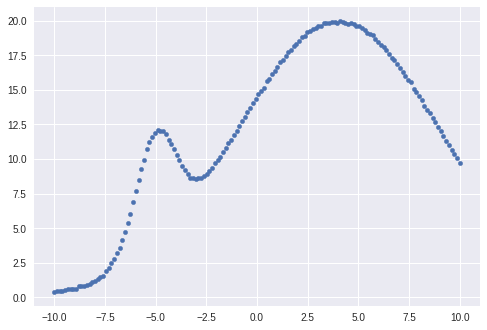
import os import math import random import numpy as np import pandas as pd import matplotlib.pyplot as plt from scipy import optimize, signal from lmfit import models #gaussianを定義(ノイズ入りデータを作るためのダミーモデル) def gaussian(x, A, μ, σ): return A / (σ * math.sqrt(2 * math.pi)) * np.exp(-(x-μ)**2 / (2*σ**2)) '''fitするためのノイズ入りデータの作成''' g_0 = [250.0, 4.0, 5.0] g_1 = [20.0, -5.0, 1.0] n = 150 x = np.linspace(-10, 10, n) # ここでは2つのガウシアンモデルを足し合わせて適当なグラフを作成 y = (gaussian(x, *g_0) + gaussian(x, *g_1)) + 0.05*np.random.randn(n) fig, ax = plt.subplots() ax.scatter(x, y, s=20) '''-----------------------------------------------------------''' '''lmfitの内蔵モデルの使用''' model_1 = models.GaussianModel(prefix='m1_')#内包モデルのガウシアンを使用 model_2 = models.GaussianModel(prefix='m2_')#内包モデルのガウシアンを使用 model = model_1 + model_2#コンポジットモデルの作成 '''lmfitの内蔵モデルの初期パラメータセット''' params_1 = model_1.make_params(center=3.0, sigma=1.0)#ガウシアンのパラメータセット print(params_1) params_2 = model_2.make_params(center=-7.0, sigma=1.0)#ガウシアンのパラメータセット print(params_2) params = params_1.update(params_2)#update methodにより辞書結合 ''' updateはPythonのビルトインメソッド(もとから入ってる標準関数みたいなもの param_1とparam_2の辞書をまとめる機能がある 一般的に同名の辞書があるとその中身が上書きされてしまうがprefix='m1_'を付けているため上書きを避けることができる。 ''' output = model.fit(y, params, x=x) fig, gridspec = output.plot(data_kws={'markersize': 5})
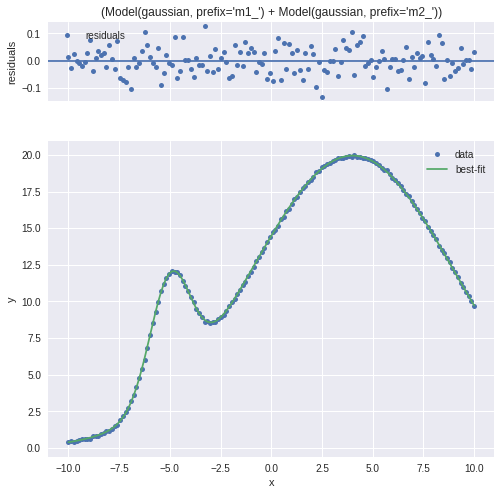
フィッティング後の残差についても出してくれます。
fit後のベストパラメータはoutput.best_valuesに格納されます。
print(output.best_values) '''-------------------------------------''' {'m2_sigma': 4.995352955273267, 'm2_center': 4.000094565660837, 'm2_amplitude': 249.88570423583715, 'm1_sigma': 1.0041137260302269, 'm1_center': -4.998780785999739, 'm1_amplitude': 20.079858838765603}
ざっと書きましたがこんなもんです。
モデル指定してモデルパラメータを設定すれば簡単にフィッティングを行うことができます。
応用的な使い方やパラメータ拘束なんかは次回書こうと思います。