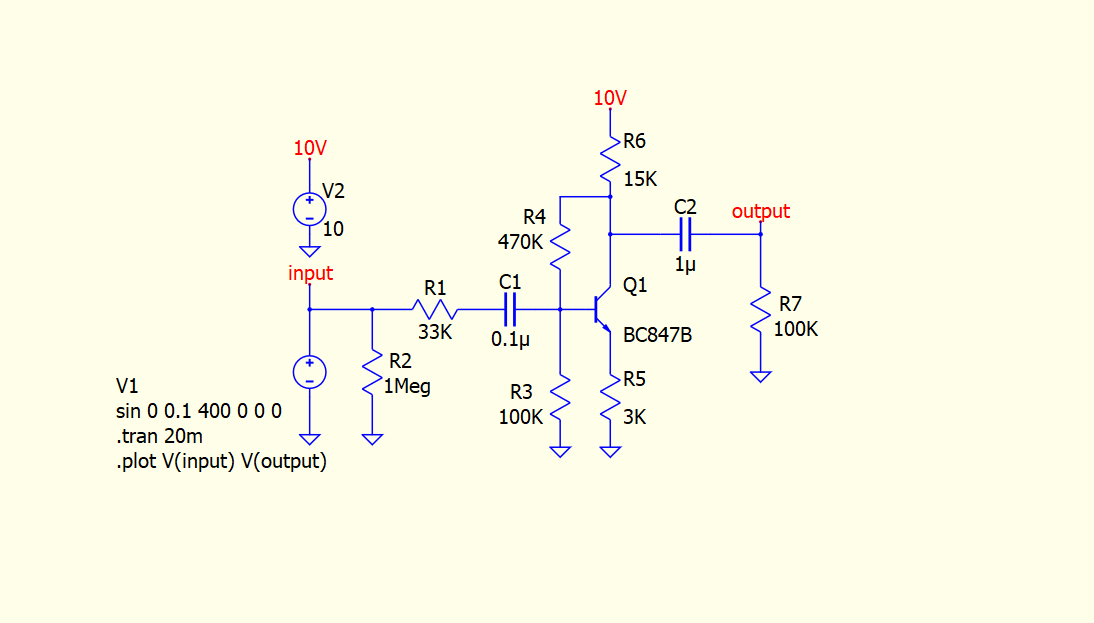
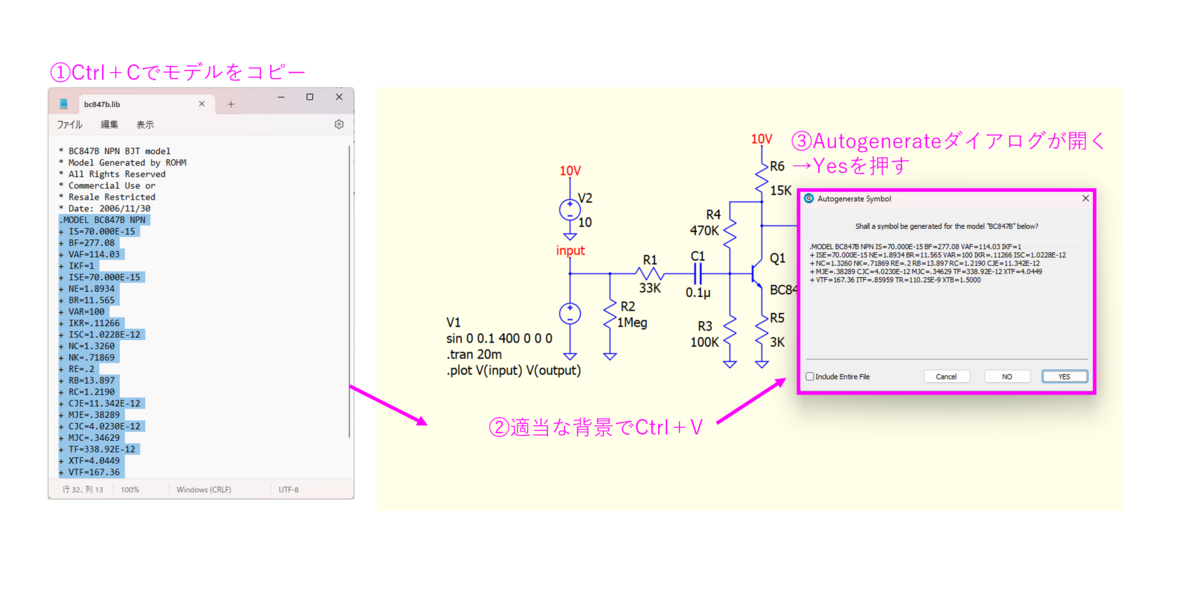
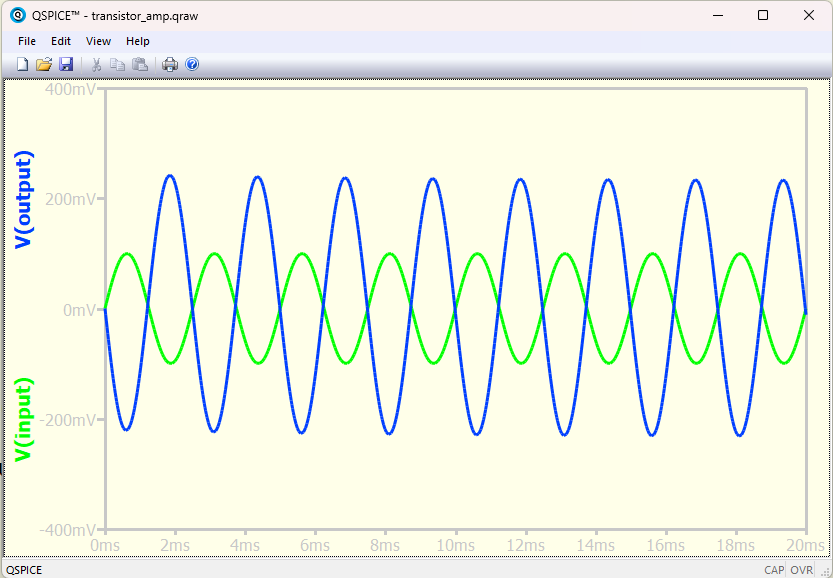
QSPICE C++基礎
まずは簡単な例として2つの信号を掛け算したものを出力するモジュールを作ってみたいと思います。
最初に回路図画面で右クリックしDraw Hierarchical entryをクリックする。
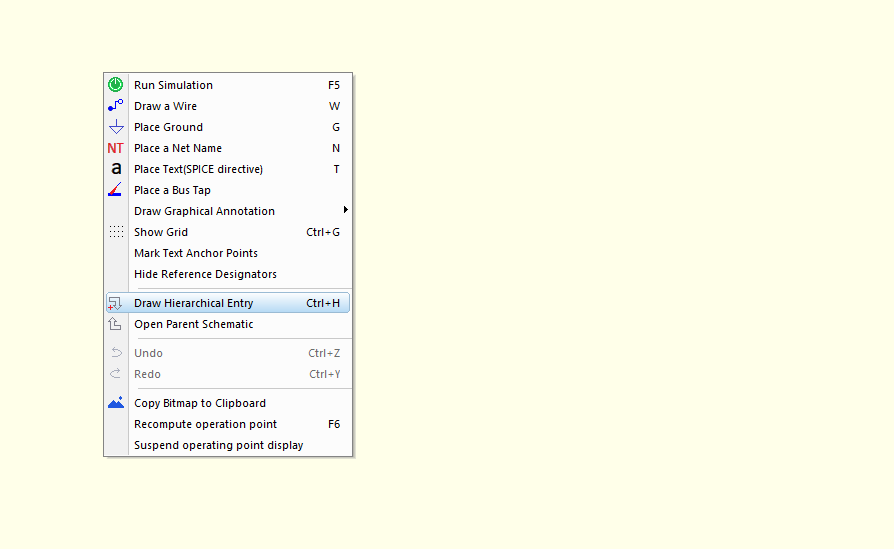
好きなサイズでブロックを配置する。

ブロック内で右クリックしピンを追加(Add port)する。

今回はinput2つとoutput一つなので以下のように追加します。
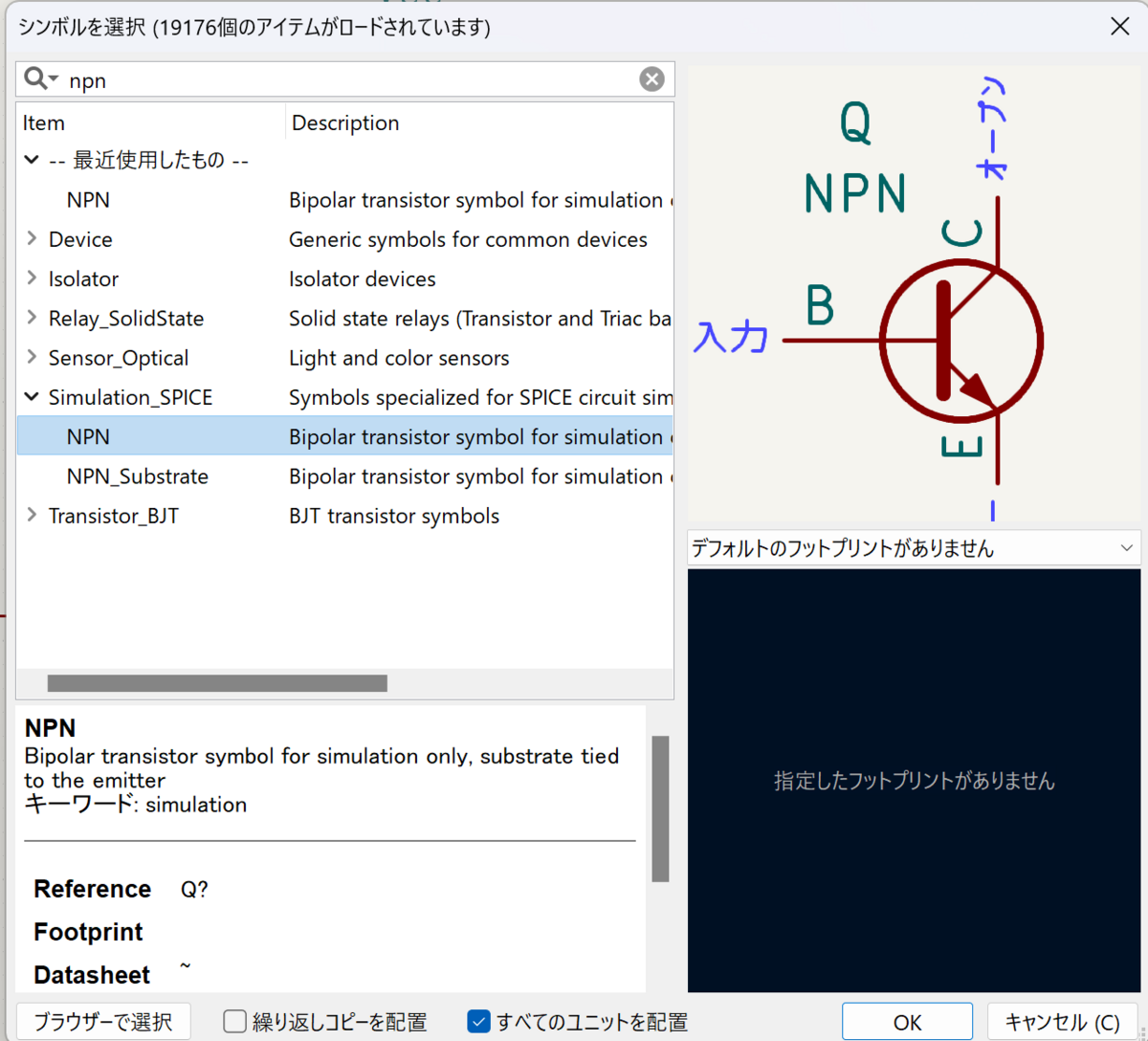
F3キーを押してSymbol Propertiesを開き、φ(.dll)を選びます。
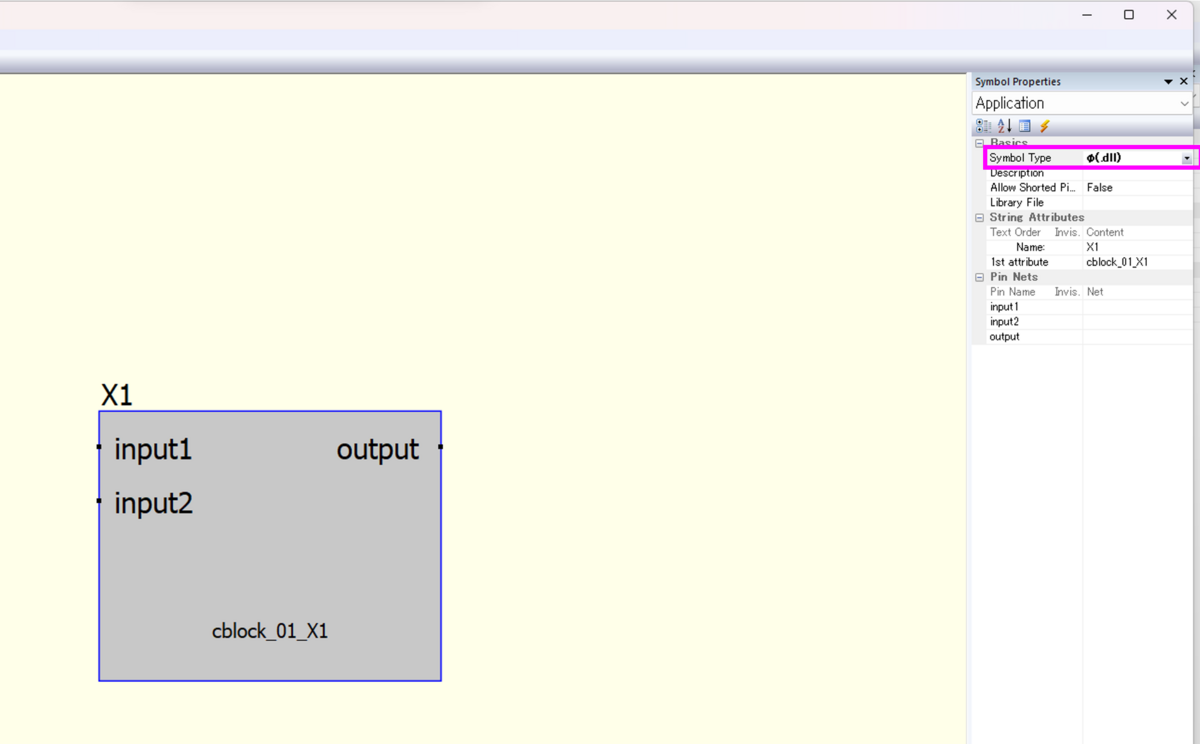
右クリックで入出力方向を指定します。
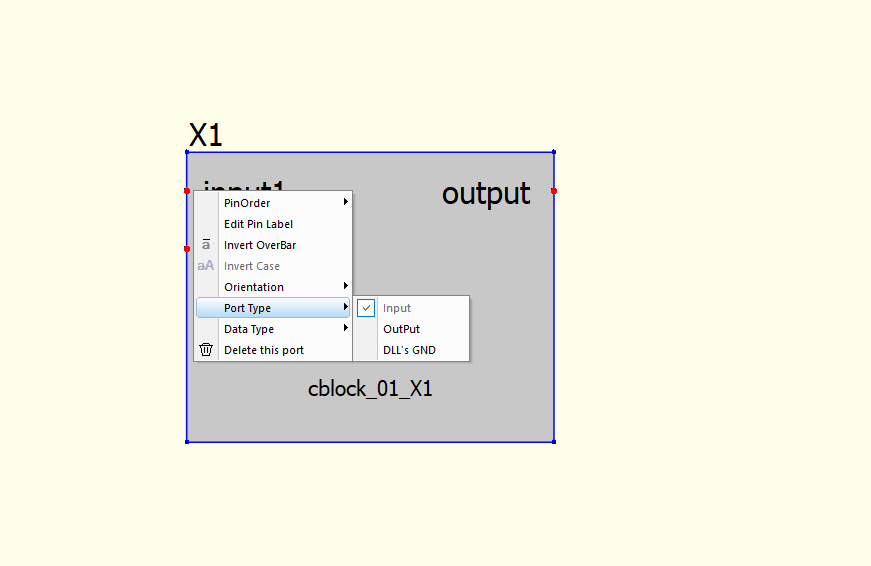
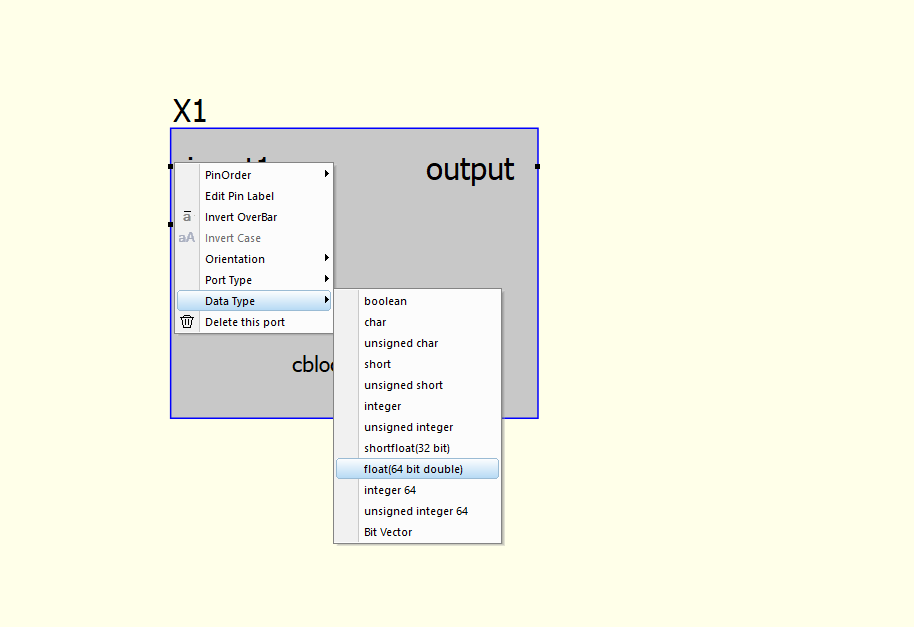
右クリックで入出力データの型を指定します。今回はfloat64にしました。
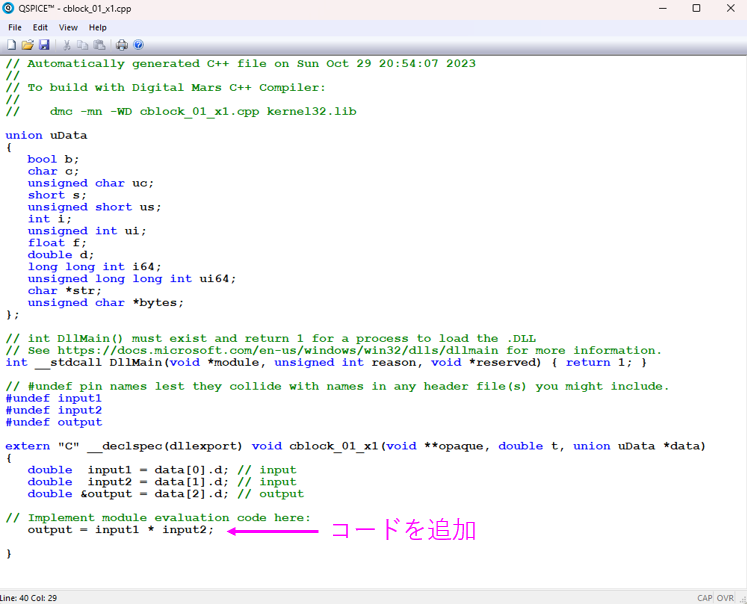
右クリックからC++interface/Open C++ Interfaceを開きます。はじめてソースを作成する場合テンプレートより作成しますか?というダイアログが出るのでOKを押せばよいです。

コード画面が開くので下のほうにあるImplement module evaluation code hereの下にユーザーのコードを記述します。今回は入力同士を乗算したものを出力する単純なコードを記述しました。
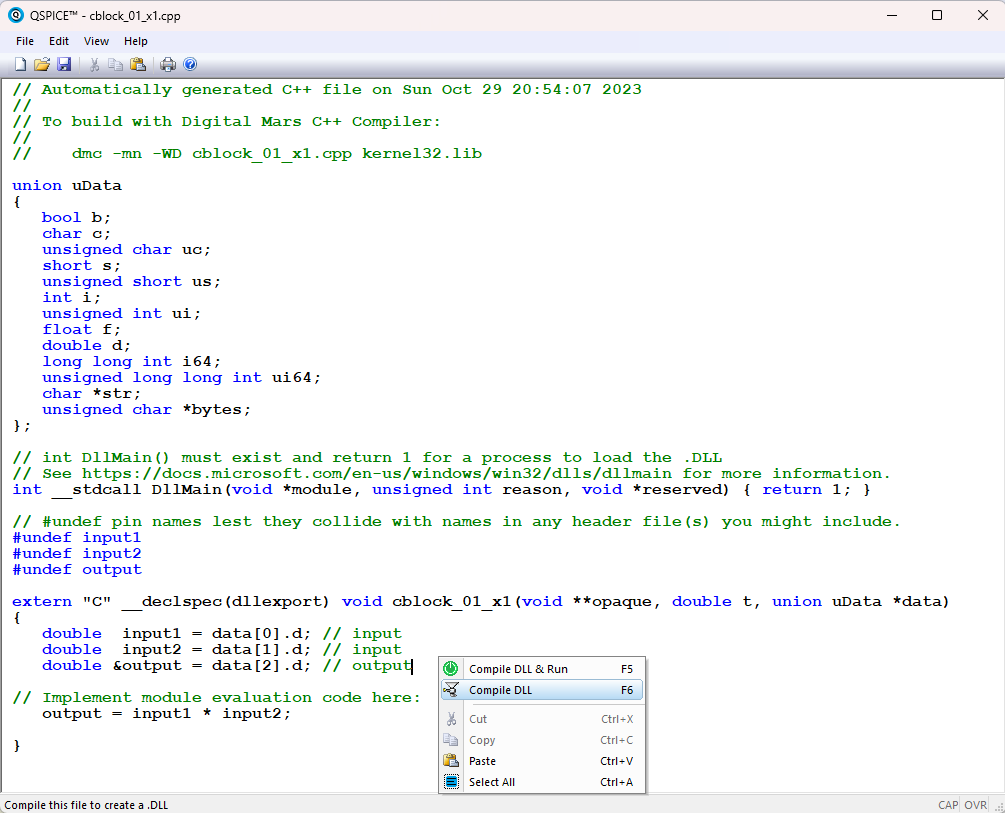
コードが書き終わったら右クリックからCompile DLLをクリックしdllを作成します。ここでエラー含め、コンパイラから怒られたら適宜修正をしてやり直してください。
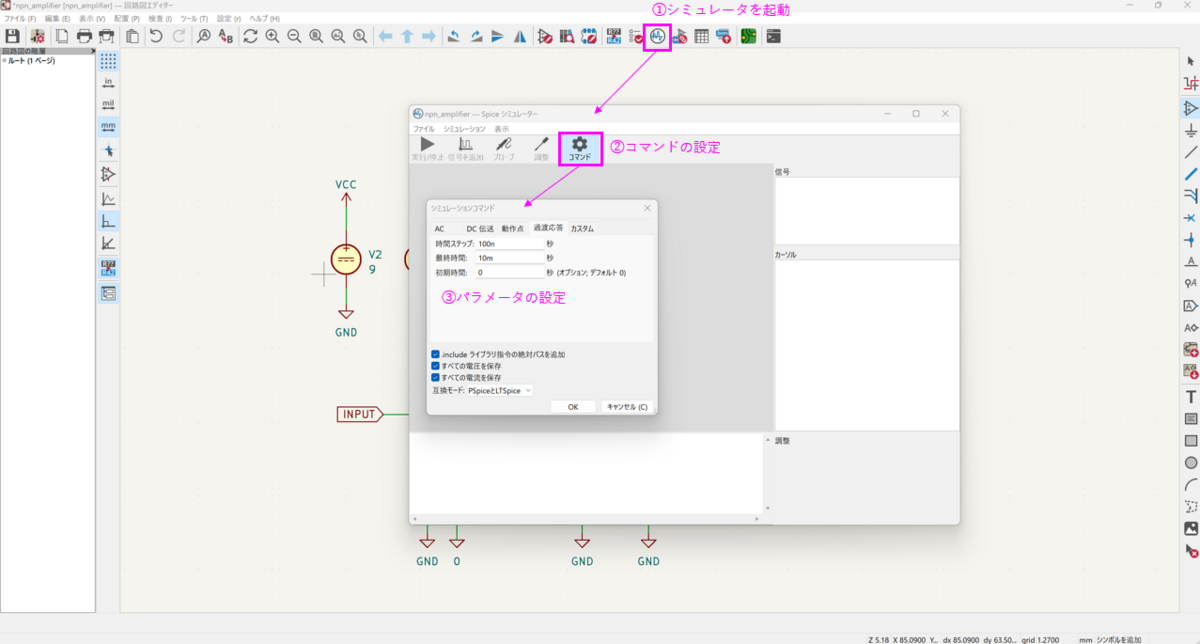
最後に回路画面に戻って信号源の配置、.tranコマンド、plotコマンドを好みで設定してください。

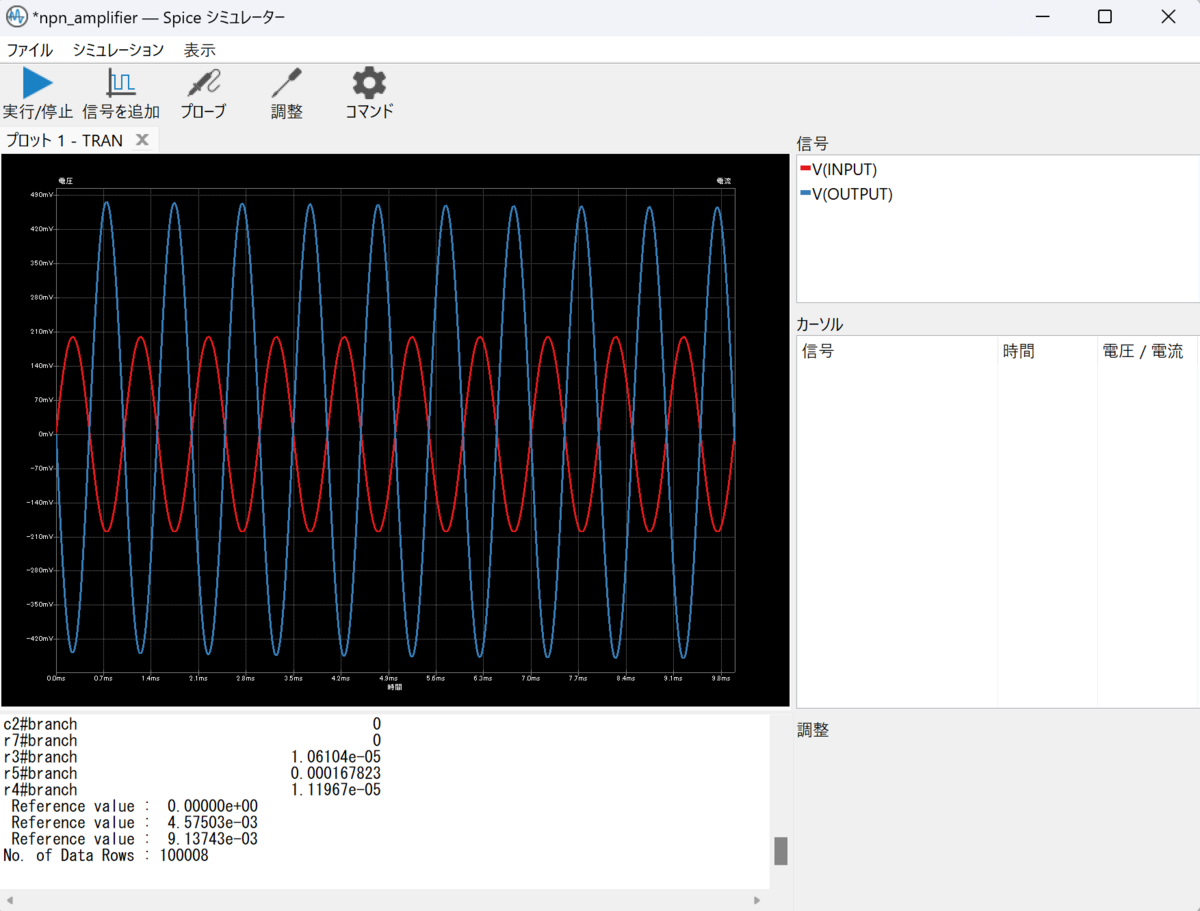
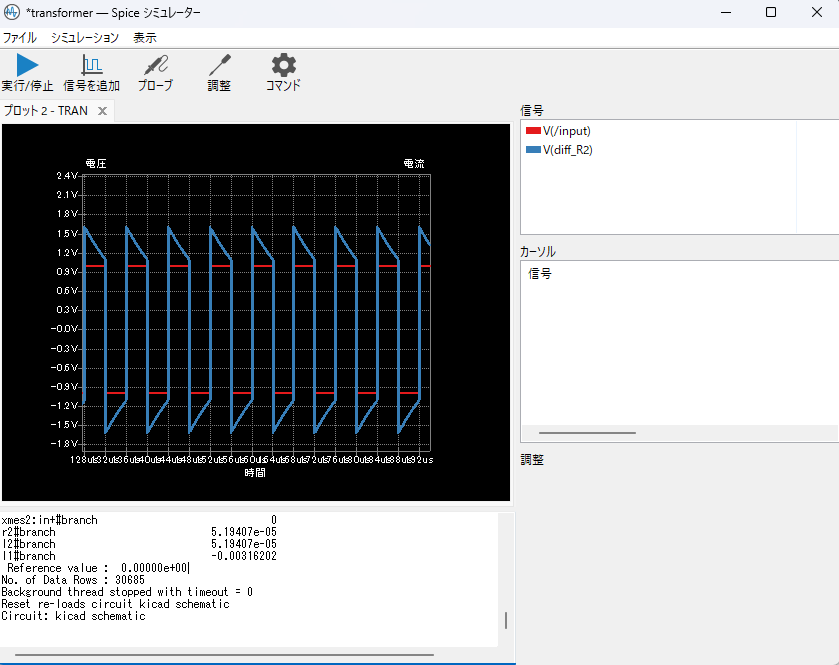
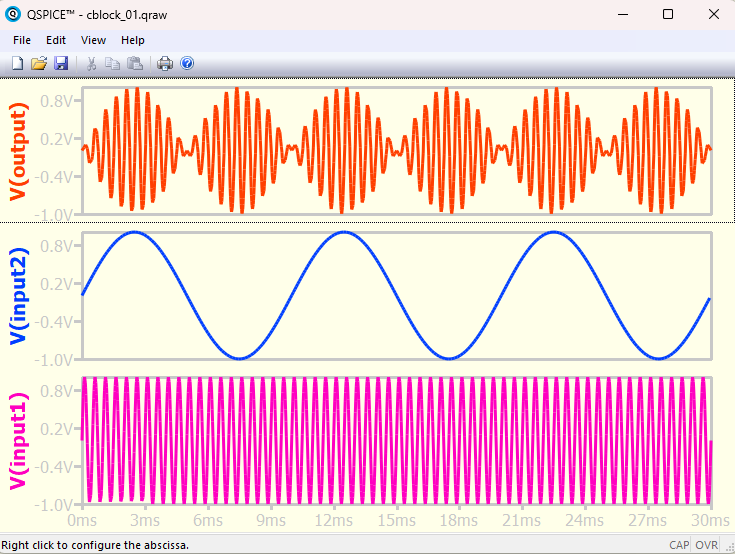
シミュレーションを実行し以下のような波形が出てくればOKです。
その他Tips
最後にその他Tipsを紹介して終わろうと思います。
robdunn4/QSpice
robdunn4氏のC++ツールセットでPID制御、シリアル通信、WavIOだったり便利に使えるものがそろっています。
https://github.com/robdunn4/QSpice
WavIOは任意の波形を突っ込むのに便利なので重宝しています。

PyQSPICE by nurobrum
PyLTspiceのQSPICE版です。開発当初はPyQSPICEという名前で開発されていたみたいですが、spicelibとして統合されLTspice、NGSpice、QSPICE、Xyceに対応しているようです。
https://github.com/nunobrum/spicelib
バッチ実行はLTと同じように扱えるのでシミュレーションレシピを組んであげて長時間回し続ける用途が良いと思います。
あとは資料向けのグラフをmatplotlibで出力するのもよいと思います。